


Section: New Results
Graphics with Uncertainty and Heterogeneous Content
Image based rendering of repetitive facades
Participants: Simon Rodriguez, Adrien Bousseau, Frederic Durand, George Drettakis.
Image Based Rendering techniques (IBR) rely on interpolation between multiple views of a scene to generate new viewpoints. One of the main requirements is that the density of input views be high enough to obtain satisfying coverage and resolution, in both preprocessing and rendering. In human-made scenes, repetitive elements can be used to alleviate this limitation when the baseline of input views is sparse. A small number of viewpoints of similar elements can be fused together to extract more information about the scene. We focus on buildings facades, which often exhibit repetitive architectural elements. We propose the following steps: such elements are extracted from input views, and used during pre-processing to generate an approximate geometry of the specific element, and to extract view-dependent effects. These data sources are then combined to perform improved rendering in an IBR context.
Plane-Based Multi-View Inpainting for Image-Based Rendering in Large Scenes
Participants: Julien Philip, George Drettakis.
Image-Based Rendering (IBR) allows high-fidelity free-viewpoint navigation using only a set of photographs and 3D reconstruction as input. It is often necessary or convenient to remove objects from the captured scenes to allow a form of scene editing for IBR. This requires multi-view inpainting of the input images. Previous methods suffer from several major limitations: they do not impose true multi-view coherence, resulting in artifacts such as blur, they do not preserve perspective during inpainting, provide inaccurate depth completion and can only handle scenes with a few tens of images. Our approach addresses these limitations by introducing a new multi-view method that performs inpainting in intermediate, locally common planes. Use of these planes results in correct perspective and multi-view coherence of inpainting results. For efficient treatment of large scenes, we present a fast planar region extraction method operating on small image clusters. We adapt the resolution of inpainting to that required in each input image of the multi-view dataset, and carefully handle image resampling between the input images and rectified planes. Our method can handle up to hundreds of input images, for indoors and outdoors environments.
Thin structures in Image Based Rendering
Participants: Theo Thonat, Abdelaziz Djelouah, Frederic Durand, George Drettakis.
One of the key problem in Image Based Rendering (IBR) methods is the rendering of regions with incorrect 3D reconstruction. Thin structures, with their lack of texture and distinctive features, are another important common source of 3D reconstruction errors. They are present in most urban pictures and represent a standard failure case for reconstruction algorithms, and state of the art rendering methods exhibit strong artifacts. In this project, we propose to detect and segment fences in urban setup for IBR applications. We use the assumption that thin structures lie on a 3D surface. We propose a multi-view approach to compute the thin structures images segmentation and its associated alpha matting. Finally, we propose also a new IBR algorithm to render these thin structures.
Handling reflections in Image-Based Rendering
Participants: Theo Thonat, Frederic Durand, George Drettakis.
In order to render new viewpoints, current Image Based Rendering (IBR) techniques use approximate geometry to warp and blend images from close viewpoints. They assume the scene materials are mostly diffuse, and they assume only a direct look at the geometry is enough. These assumptions fail in the case of specular surfaces such as windows. Dealing with reflections in an IBR context first requires identifying what are the diffuse and the specular color layers in the input images. The challenge is then to correctly warp the specular layers since the normals of the reflective surfaces might be not reliable.
Material capture
Participants Valentin Deschaintre, Miika Aittala, Frederic Durand, George Drettakis, Adrien Bousseau.
Convenient material acquisition is a complicated process, current methods are based on strong assumptions or limitations. Acquisition of spatially varying materials complete models is currently limited to specific materials or complex setups requiring multiple pictures with varying light and view positions.
This work aims at acquiring a material's Spatially-Varying BRDF using a single flash picture. We introduce procedural synthetic data generation and deep learning to mitigate the need of material and environment assumptions.
With fewer pictures used in the material acquisition process, comes more ambiguities in the explanation of the lighting behaviour. With one shot acquisition, important effects can be missed or misunderstood because of the lighting or view point. Current "lightweight" methods use various assumptions regarding materials. We use training to learn important ambiguities and how to solve them from the dataset, giving our network the capacity to handle the inherent uncertainty of one picture material acquisition.
Accommodation and Comfort in Head-Mounted Displays
Participants: George-Alex Koulieris, George Drettakis.
Head-mounted displays (HMDs) often cause discomfort and even nausea. Improving comfort is therefore one of the most significant challenges for the design of such systems. We evaluated the effect of different HMD display configurations on discomfort. We did this by designing a device to measure human visual behavior and evaluate viewer comfort. In particular, we focused on one known source of discomfort: the vergence-accommodation (VA) conflict. The VA conflict is the difference between accommodative and vergence response. In HMDs the eyes accommodate to a fixed screen distance while they converge to the simulated distance of the object of interest, requiring the viewer to undo the neural coupling between the two responses. Several methods have been proposed to alleviate the VA conflict, including Depth-of-Field (DoF) rendering, focus-adjustable lenses, and monovision. However, no previous work had investigated whether these solutions actually drive accommodation to the distance of the simulated object. If they did, the VA conflict would disappear, and we would expect comfort to improve. We designed the first device that allows us to measure accommodation in HMDs, and we used it to obtain accommodation measurements and to conduct a discomfort study, see Fig. 7. The results of the first experiment demonstrated that only the focus-adjustable-lens design drives accommodation effectively, while other solutions do not drive accommodation to the simulated distance and thus do not resolve the VA conflict. The second experiment measured discomfort. The results validated that the focus-adjustable-lens design improves comfort significantly more than the other solutions.
|
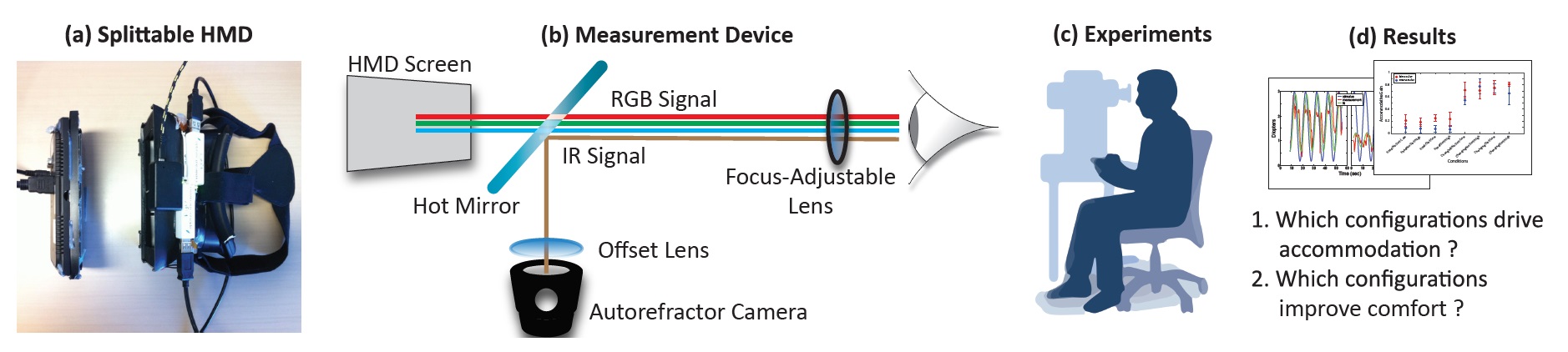
This work [11] is a collaboration with Martin S. Banks and Bee Bui from University of California, Berkeley. The work was published in a regular issue of the journal Transactions on Graphics and presented at the ACM SIGGRAPH conference in Los Angeles, USA, 2017.
Focus-tunable and Fixed Lenses and Stereoscopic 3D Displays
Participants: George-Alex Koulieris, George Drettakis.
Stereoscopic 3D (S3D) displays provide an enhanced sense of depth by sending different images to the two eyes. But these displays do not reproduce focus cues (blur and accommodation) correctly. Specifically, the eyes must accommodate to the display screen to create sharp retinal images even when binocular disparity drives the eyes to converge to other distances. This mismatch causes discomfort, reduces performance, and distorts 3D percepts. We developed two techniques designed to reduce vergence-accommodation conflicts and thereby improve comfort, performance, and perception. One uses focus-tunable lenses between the display and viewer's eyes. Lens power is yoked to expected vergence distance creating a stimulus to accommodation that is consistent with the stimulus to vergence. This yoking should reduce the vergence-accommodation mismatch. The other technique uses a fixed lens before one eye and relies on binocularly fused percepts being determined by one eye and then the other, depending on simulated distance. This is meant to drive accommodation with one eye when simulated distance is far and with the other eye when simulated distance is near. We conducted performance tests and discomfort assessments with both techniques and with conventional S3D displays (see Fig. 8). We also measured accommodation. The focus-tunable technique, but not the fixed-lens technique, produced appropriate stimulus-driven accommodation thereby minimizing the vergence-accommodation conflict. Because of this, the tunable technique yielded clear improvements in comfort and performance while the fixed technique did not. The focus-tunable lens technique therefore offers a relatively easy means for reducing the vergence-accommodation conflict and thereby improving viewer experience.
|
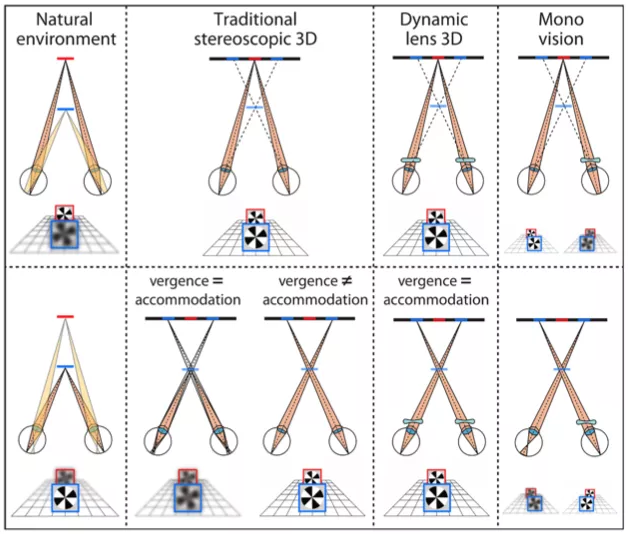
This work is a collaboration with Martin S. Banks from University of California, Berkeley, Paul V. Johnson from Apple, Joohwan Kim, Nvidia, Jared AQ Parnell and Gordon D. Love, Durham University, UK. The work was published in the proceedings of SPIE and presented at SPIE Opto 2017 conference, San Francisco, USA.
Applications of Visual Perception to Virtual Reality Rendering
Participants: George-Alex Koulieris
Over the past few years, virtual reality (VR) has transitioned from the realm of expensive research prototypes and military installations into widely available consumer devices. But the high pixel counts and frame rates of current commodity devices more than double the rendering costs of 1920x1080 gaming, and next-generation HMDs could easily double or triple costs again. As a result, VR experiences are limited in visual quality, performance, and other capabilities. Human visual perception has repeatedly been shown to be important to creating immersion while keeping up with increasing performance requirements. Thus, an understanding of visual perception and its applications in real-time VR graphics is vital for HMD designers, application developers, and content creators. In this course we began with an overview of the importance of human perception in modern virtual reality. We accompanied this overview with a dive into the key characteristics of the human visual system and the psychophysical methods used to study its properties. After laying the perceptual groundwork, we presented three case studies outlining the applications of human perception to improving the performance, quality, and applicability of VR graphics. Finally, we concluded with a forward looking discussion, highlighting important future work and open challenges in perceptual VR, and a questions session for more in-depth audience interaction.
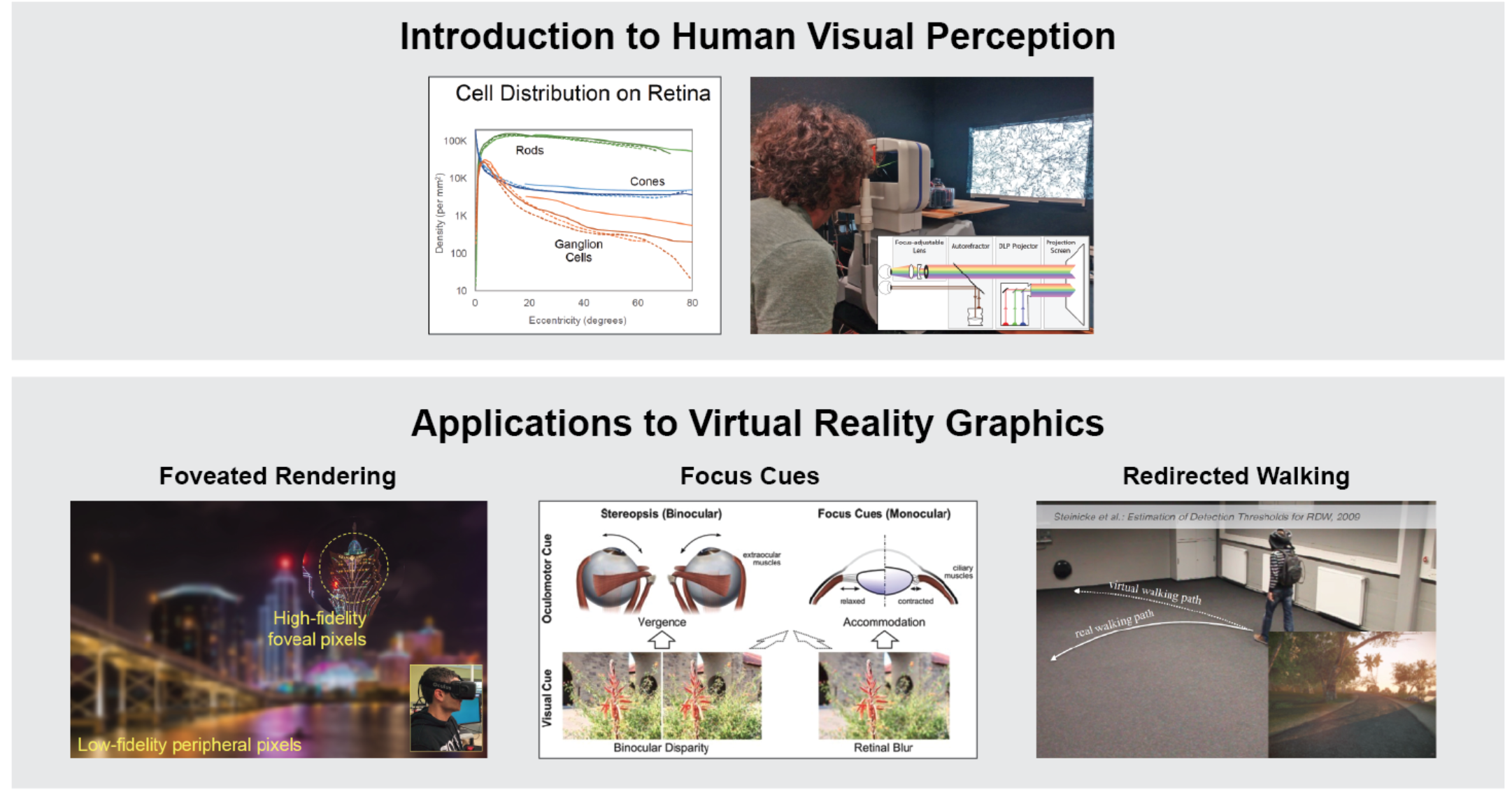
This work is a collaboration with Anjul Patney and Joohwan Kim, Nvidia, Marina Zanolli, Oculus VR, Gordon Wetzstein, Stanford University and Frank Steinicke, University of Hamburg. The course was presented at ACM SIGGRAPH 2017, Los Angeles, USA.
Real-time Binocular Tone Mapping
Participants: George-Alex Koulieris, George Drettakis
In real-world scenes, luminance values can simultaneously span several orders of magnitude. The human visual system has evolved such it can comfortably perceive this vast luminance gamut via adaptation mechanisms both in the eyes and the brain. Conventional displays can not reproduce such enormous dynamic ranges since their contrast ratio is severely limited. As a result, simulations of natural scenes significantly deviate from real-world percepts. Tone-mapping techniques approximate the appearance of high dynamic range scenes in limited dynamic range media. However, there exists an inherent trade-off between simultaneously inducing both a high dynamic range perception and preserving contrast in fine-scale details. We will alleviate this trade-off by capitalizing on the properties of the visual system's binocular fusion processes during dichoptic stimulation, i.e., when a different image is shown to each eye.
To be submitted: This work is an ongoing collaboration with Martin S. Banks, University of California, Berkeley, Rafal Mantiuk, University of Cambridge, and Fredo Durand, MIT.
A novel objective method for the assessment of binocular accommodative facility: A pilot study in a young adult population
Participants: George-Alex Koulieris
Accommodative facility (AF) is a clinical test used to evaluate the ability of the visual system to alter accommodation rapidly and accurately when the dioptric stimulus to accommodation is situated between two different distances. AF can be evaluated in monocular and binocular testing, providing a direct evaluation of the dynamics of the accommodative response. We investigated the validity of measuring the binocular accommodative facility using Hart charts in conjunction with the Grand Seiko Auto Ref/Keratometer in young participants. The main objective of the study was to propose a novel objective method to assess binocular accommodative facility in quantitative terms.
To be submitted: This work is an ongoing collaboration with Jesus Vera-Vilchez and Raimundo Jimenez Rodriguez, University of Granada, Spain.
Efficient Thin Shell Sounds
Participants: Gabriel Cirio, George Drettakis.
Thin shells, i.e. solids that are thin in one dimension compared to the other two, often produce rich and recognizable sounds when struck: from containers like a trash can or a plastic bottle, to musical instruments like a cymbal or a gong. Thin shells are notoriously difficult and expensive to simulate due to their nonlinear behavior under large excitations. To synthesize the sound generated by thin shells, we first reduce the problem to a small modal subspace, and compute all the required quantities directly in the subspace. We then further speed up the simulation by computing nonlinear dynamics using only a subset of low frequency vibrations, since these are responsible for most nonlinear phenomena, and use a frequency coupling to drive the remaining high frequency vibrations. Finally, we approximate the chaotic regime that can emerge in some thin shells (such as gongs and cymbals) by diffusing the power spectrum of the sound directly in the frequency domain, following a phenomenological approach to wave turbulence. We can produce rich and complex sounds for a wide range of behaviors with a computational cost orders of magnitude smaller than previous approaches.
This work is an ongoing collaboration with Changxi Zheng and Etian Grinspun from Columbia University in New York, and is supported by the EU H2020 Marie Sklodowska-Curie project PhySound.
Aether: An Embedded Domain Specific Sampling Language for Monte Carlo Rendering
Participant: Frederic Durand
Implementing Monte Carlo integration requires signifcant domain expertise. While simple samplers, such as unidirectional path tracing, are relatively forgiving, more complex algorithms, such as bidirectional path tracing or Metropolis methods, are notoriously diffcult to implement correctly.We propose Aether, an embedded domain specifc language for Monte Carlo integration, which offers primitives for writing concise and correct-by-construction sampling and probability code. The user is tasked with writing sampling code, while our compiler automatically generates the code necessary for evaluating PDFs as well as the book keeping and combination of multiple sampling strategies. Our language focuses on ease of implementation for rapid exploration, at the cost of run time performance. We demonstrate the effectiveness of the language by implementing several challenging rendering algorithms as well as a new algorithm, which would otherwise be prohibitively difficult.
The work [6] was published in a regular issue of the journal Transactions on Graphics and presented at the ACM SIGGRAPH conference in Los Angeles, USA, 2017.
Deep bilateral learning for real-time image enhancement
Participant: Frederic Durand
Performance is a critical challenge in mobile image processing. Given a reference imaging pipeline, or even human-adjusted pairs of images, we seek to reproduce the enhancements and enable real-time evaluation. For this, we introduce a new neural network architecture inspired by bilateral grid processing and local affine color transforms. Using pairs of input/output images, we train a convolutional neural network to predict the coefficients of a locally-affine model in bilateral space. Our architecture learns to make local, global, and content-dependent decisions to approximate the desired image transformation. At runtime, the neural network consumes a low-resolution version of the input image, produces a set of affine transformations in bilateral space, upsamples those transformations in an edge-preserving fashion using a new slicing node, and then applies those upsampled transformations to the full-resolution image. Our algorithm processes high-resolution images on a smartphone in milliseconds, provides a real-time viewfinder at 1080p resolution, and matches the quality of state-of-the-art approximation techniques on a large class of image operators. Unlike previous work, our model is trained off-line from data and therefore does not require access to the original operator at runtime. This allows our model to learn complex, scene-dependent transformations for which no reference implementation is available, such as the photographic edits of a human retoucher.
The work [10] was published in a regular issue of the journal Transactions on Graphics and presented at the ACM SIGGRAPH conference in Los Angeles, USA, 2017.